Formatos de los ficheros
Los libros de la Biblioteca se encuentran en ficheros en formato PDF o en formato DJVU:
- Formato PDF:

Es un formato muy conocido y extendido. Se trata de un formato de almacenamiento para documentos digitales que es independiente del sistema operativo que se esté manejando. Para poder acceder a estos documentos es preciso instalar en el ordenador algún visor de ficheros PDF; aunque, dada la extensión del mismo, prácticamente todos los sistemas informáticos instalan por defecto algún visor. Además del que esté instalado por defecto en nuestro sistema, siempre es posible instalar algún otro visor. Se recomienda utilizar algún visor que permita mostrar las características adicionales de los ficheros tales como el índice de marcadores.
- Formato DJVU: (pronunciado deja-vu)

Se trata de un formato bastante menos conocido que el PDF, aunque ofrece varias ventajas frente a él. Principalmente la de que con este formato se obtiene generalmente una ratio de compresión bastante superior a la del formato PDF, lo que implica que los ficheros en formato DJVU suelen ocupar mucho menos espacio que los ficheros PDF, por lo que se descargan con más rapidez y, cuando se trata de ficheros de gran extensión, para poderlos ver, no es necesario un ordenador tan potente como el que se precisaría para visualizar el correspondiente PDF. Para saber más sobre los ficheros DJVU puede pulsarse este enlace.
Al igual que en los ficheros PDF, los ficheros DJVU no son accesibles si previamente no se instala el oportuno visor. Pero al tratarse de un formato menos extendido, no es normal que los sistemas informáticos incorporen por defecto dicho visor. En la mayor parte de los casos es preciso instalarlo expresamente, aunque ello no es especialmente difícil. En los siguientes enlaces se puede acceder a distintos visores, instalando cualquiera de ellos, quedará nuestro sistema preparado para poder manejar este tipo de ficheros:
- Sistemas Windows: Hay numerosos visores, entre los más extendidos se encuentran DjVuLibre o WinDjView
- Sistemas MacOS: Para el sistema operativo de los ordenadores de la marca Apple existe una versión de DJVU libre, así como de WinDjView que, para este sistema operativo, se denomina MacDjView.
- Sistemas Linux: En ellos es donde resulta más sencillo instalar el visor, pues todas las distribuciones de Linux incluyen el paquete djvulibre.
Aunque se recomienda el uso del formato DJVU siempre que sea posible, se es consciente de que el formato PDF está mucho más extendido, y por ello se ha procurado que siempre exista una versión en PDF de la obra en cuestión. Aunque a veces dicha versión no tenga todas las características de la versión en DJVU.
Modificaciones en los ficheros originales
Como regla, las obras que no han sido expresamente digitalizadas para la Biblioteca se encuentran tal y como estaban en su repositorio original. No obstante, en algunas ocasiones en las que el fichero era difícilmente legible, u ocupaba demasiado espacio en disco (con la subsiguiente exigencia de tiempo y potencia en el ordenador para poderlo descargar y procesar), se ha procedido a introducir cambios dirigidos a reducir su tamaño en disco y mejorar su legibilidad. Entre esos cambios puede destacarse:
- La supresión de las páginas en blanco, que sólo tienen sentido en una obra concebida para ser impresa; pero no en un libro pensado para ser leído en pantalla.
- La reducción de los márgenes de las páginas, que contribuye a reducir el tamaño de las imágenes que las contienen.
- La eliminación de manchas, subrayados, anotaciones a mano o sellos de bibliotecas que se encontraban en el ejemplar físico original del libro y pasaron a la versión escaneada, pero que dificultan la legibilidad y restan precisión al proceso de OCR.
- La reducción de la resolución de la imagen.
- El añadido de índice de marcadores, o la mejora del que acaso existiera en origen.
En muchas ocasiones estos cambios se realizan sólo en la versión en DJVU, que es la que en el diseño de la BJD-AR se considera siempre versión «principal».
Características de los ficheros: OCR e índice de marcadores
Los ficheros digitales de la Biblioteca Jurídica Digital Antonio Reverte no son ficheros de texto, sino ficheros de imagen; es decir: cada una de sus páginas es una reproducción de la página correspondiente del libro original. Una especie de «fotografía digital». Esto implica que estos ficheros tienden a ser de gran tamaño. Para reducir este tamaño, y asumiendo que, como regla, los libros de la Biblioteca serán consultados en pantalla, y no impresos, en muchos de ellos se ha procedido a eliminar las páginas que están totalmente en blanco; aunque tal vez contuvieran alguna anotación o sello del propietario original del libro. Y es que la finalidad de esta Biblioteca no es «bibliófila»: No importa el libro tal y como era el ejemplar físico que se escaneó, sino su contenido intelectual desde el punto de vista del autor; de tal modo que, como regla, las páginas sin contenido se eliminan del fichero.
El hecho de que las páginas de los ficheros sean, en realidad, imágenes, significa también que, en principio, para el ordenador el texto contenido en las páginas no existe, sino que las páginas son vistas como meras fotografías, sin poder acceder a su contenido. Esto significa, en términos prácticos, que, en principio, no es posible realizar búsquedas de texto dentro de los libros digitales procedentes del escaneado de un libro físico. Este inconveniente, no obstante, se puede aminorar mediante el proceso informático denominado OCR.
OCR
En la terminología informática se denomina OCR (siglas de Optical Character Recognition, o, en español, Reconocimiento Óptico de Caracteres) al procedimiento por el que en una imagen que contiene texto se identifican los caracteres que componen dicho texto. Mediante este procedimiento es posible añadir al fichero PDF o DJVU una capa de texto invisible que permita realizar búsquedas de texto en las imágenes.
Téngase en cuenta, no obstante, que el OCR no ofrece una fiabilidad absoluta. La precisión de los resultados depende de numerosos factores tales como la tipografía utilizada por el libro, el idioma o el estado de sus páginas y la calidad del escaneo. Asimismo las imágenes superpuestas sobre el texto, tales como sellos, marcas de subrayado o, incluso, anotaciones a mano realizadas por algún lector, afectan negativamente a la precisión del reconocimiento óptico de caracteres. De ahí que en ocasiones estos elementos se hayan suprimido de las páginas escaneadas. Aunque, como este tipo de «limpieza» de las páginas no se puede automatizar, y puede llevar bastante tiempo, esta tarea sólo se ha realizado en algunas ocasiones.
No todos los libros de la Biblioteca han sido sometidos al proceso de OCR. Algunos estaban en tan mal estado que no era razonable siquiera intentarlo; otros se imprimieron con una tipografía que se presta poco a ello, como por ejemplo los libros alemanes del siglo XIX impresos en caracteres góticos, o algún libro cuya tipografía imita la letra a mano. Asimismo en los libros generados directamente en formato DJVU, lo normal es que la versión en PDF generada a partir de ella carezca de OCR, pues las herramientas informáticas que se utilizan para tal conversión no conservan en el fichero convertido el OCR del fichero original.

Índice de marcadores
Un índice de marcadores (al que, en ocasiones, en la jerga informática se le denomina «outline»), es una utilidad consistente en la inclusión de un conjunto de «marcadores» que apuntan a las distintas partes de un libro digital. Estos «marcadores» son, en realidad, enlaces que permiten saltar directamente a cierta página y que, por lo tanto, no forman parte del libro, propiamente dicho. Si el programa visor del fichero nos muestras el listado de los marcadores disponibles, y estos, a su vez, reproducen la estructura del libro, de tal manera que tengamos siempre a la vista su índice y podamos acceder con rapidez a los distintos apartados del libro, tenemos lo que, a falta de una palabra más clara, hemos denominado «índice de marcadores».
Como explicar con palabras lo que es un índice de marcadores es más difícil que verlo en funcionamiento, en la imagen del próximo párrafo se muestra un libro con su correspondiente índice de marcadores en el margen izquierdo:
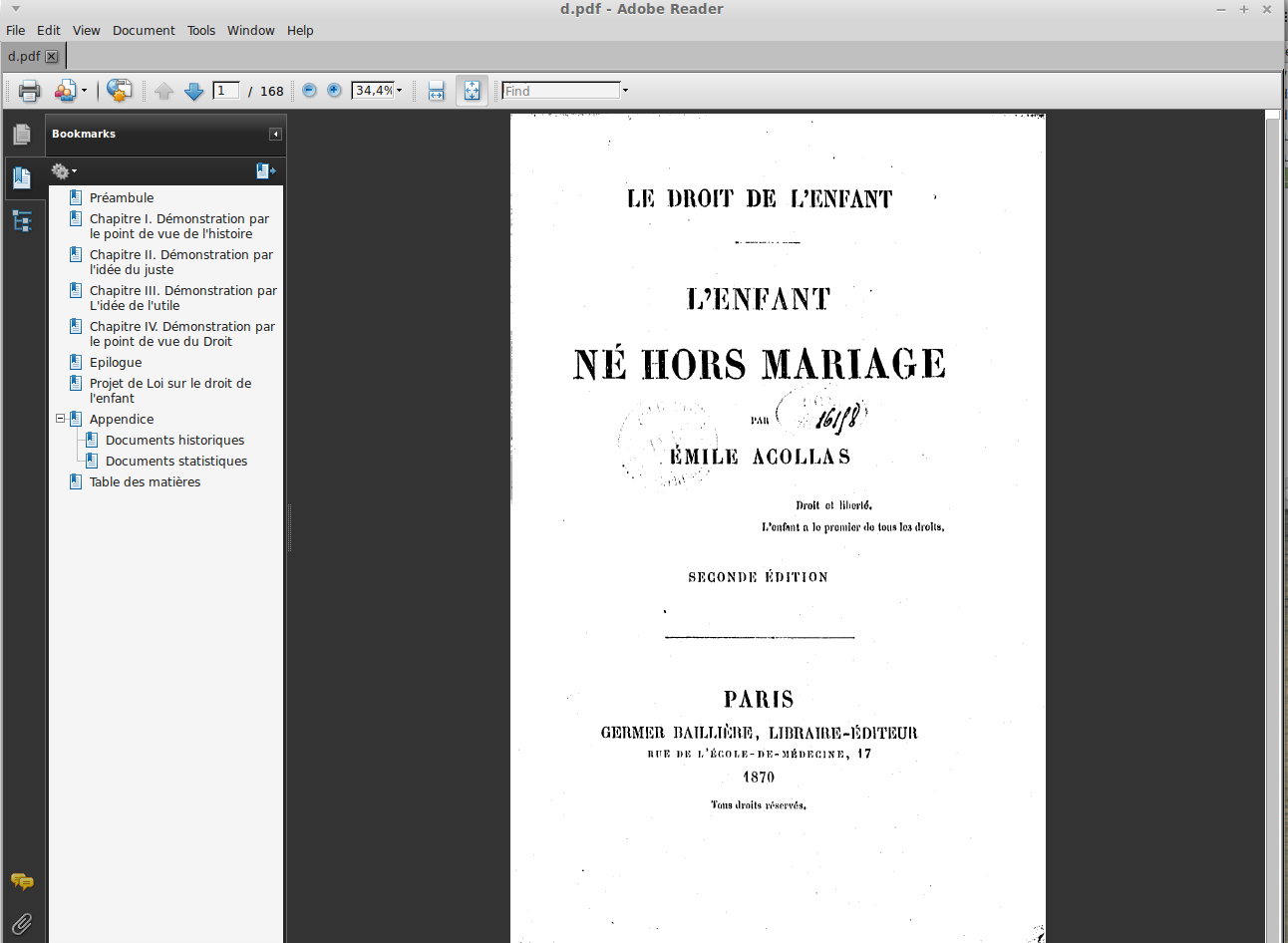
En libros de gran extensión, el contar con un índice de marcadores resulta extremadamente útil para localizar el fragmento del libro que nos interesa. Obsérvese en la imagen anterior como las distintas entradas del índice de marcadores pueden tener distintos niveles, representativos de las distintas secciones y subsecciones del libro.
La gran generalidad de visores de los formatos DJVU y PDF permiten mostrar este tipo de índices, si bien, en ocasiones, esa utilidad no está activada por defecto. Así, por ejemplo, en Adobe Acrobat, que es el visor de ficheros PDF usado por defecto en la mayor parte de los ordenadores, para ver él índice interactivo hay que activar tal posibilidad en el menú View/Navitation Panels/Bookmarks (o, si el menú está en español, Ver/Paneles de navegación/Marcadores).
Aunque no todos, la mayoría de los libros de la Biblioteca disponen de un índice de marcadores, si bien éste no siempre está totalmente detallado. Y así, por ejemplo, es posible que en un libro cuya estructura tenga partes, capítulos, secciones, subsecciones y parágrafos, el índice de marcadores sólo muestre las partes y los capítulos. Asimismo, como la conversión entre formatos no siempre respeta el índice de marcadores, y éste tiene que ser generado a mano en el fichero convertido, no siempre el índice de marcadores es idéntico en las versiones PDF y DJVU.